
روشهای زیادی برای بهبود سئو سایت وجود دارد که چندان پیچیده یا زمان بر نیستند. یکی از این روش ها ساخت فایل robots.txt است.
این فایل متنی کوچک بخشی از هر وب سایت در اینترنت است، اما بسیاری از افراد اطلاعی در مورد آن ندارند. برای ساخت فایل robots.txt
نیازی به داشتن دانش فنی نداریم. در ادامه مراحل ساخت فایل robots.txt را مورد بررسی قرار می دهیم. در صورتیکه می خواهید در مورد
ابزارهای سئو بیشتر بدانید، پیشنهاد می کنیم مقاله معرفی برخی ابزارهای مهم چک سئو را مطالعه فرمایید.
فایل Robots.txt چیست؟
فایل Robots.txt فایلی است که به عنکبوتهای موتورهای جستجو میگوید که در صفحات یا بخشهای خاصی از یک وبسایت نخزند.
اکثر موتورهای جستجوی اصلی ( از جمله گوگل، بینگ و یاهو ) درخواست های Robots.txt را می شناسند و به آنها احترام می گذارند.
چرا فایل robots.txt مهم است؟
فرض کنید یک موتور جستجو در شرف بازدید از یک سایت است، قبل از بازدید از صفحه هدف، robots.txt را برای دستورالعمل بررسی می کند.
انواع مختلفی از فایلهای robots.txt وجود دارد. فرض کنید موتور جستجو این نمونه فایل robots.txt را پیدا می کند:
User-agent: *
Disallow: /
ستاره بعد از "user-agent" به این معنی است که فایل robots.txt برای همه ربات های وب که از سایت بازدید می کنند، اعمال می شود.
اسلش بعد از “Disallow” به ربات می گوید که از هیچ صفحه ای در سایت بازدید نکند.شاید تعجب کنیم که چرا ممکن است کسی بخواهد
مانع از بازدید رباتهای وب از سایت خود شود.یکی از اهداف اصلی سئو این است که موتورهای جستجو را به خزیدن آسان در سایت ما
وادار کند تا رتبه ما را افزایش دهند.احتمالاً صفحات زیادی در وب سایت ما وجود دارد. اگر یک موتور جستجو در سایت ما بخزد
در تک تک صفحات ما می خزد.
3 دلیل اصلی برای استفاده از فایل robots.txt وجود دارد:
مسدود کردن صفحات غیر عمومی: گاهی اوقات صفحاتی در سایت خود داریم که نمی خواهیم ایندکس شوند. برای مثال، ممکن است یک
نسخه staging از یک صفحه یا یک صفحه لاگین داشته باشیم. این صفحات میبایست وجود داشته باشند، اما نمی خواهیم افراد به صورت
تصادفی وارد این صفحات شوند. اینها مواردی هستند که از robots.txt به منظور مسدود کردن این صفحات برای خزندهها و
رباتهای موتور جستجو استفاده می کنیم.
به حداکثر رساندن بودجه خزیدن: اگر برای ایندکس شدن همه صفحات خود با مشکل مواجه هستیم، ممکن است با مشکل بودجه خزیدن
مواجه شویم. با مسدود کردن صفحات بیاهمیت با robots.txt، Googlebot می تواند قسمت بیشتر از بودجه خزیدن ما را روی
صفحاتی که واقعاً مهم هستند، خرج کند.
جلوگیری از ایندکس منابع: دستورات متا می توانند به خوبی Robots.txt برای جلوگیری از ایندکس شدن صفحات مورد استفاده قرار گیرند.
با این حال، دستورالعملهای متا برای منابع چند رسانه ای، مانند فایلهای PDF و تصاویر، به خوبی کار نمیکنند. اینجاست که robots.txt
وارد عمل می شود. Robots.txt به عنکبوتهای موتورهای جستجو میگوید که در صفحات خاصی در وب سایت ما نخزند.
پیدا کردن فایل robots.txt
برای پیدا کردن فایل robots.txt مسیر آسانی وجود دارد که در واقع، این روش برای هر سایتی جواب می دهد. تنها کاری که باید انجام دهیم
آن است که URL اصلی سایت را در نوار جستجوی مرورگر خود تایپ کنیم. سپس /robots.txt را به انتهای آن اضافه می کنیم.
یکی از سه حالت زیر اتفاق میفتد:
ـــ فایل robots.txt را پیدا خواهیم کرد.
ـــ یک فایل خالی پیدا خواهیم کرد.
ـــ یک صفحه 404 دریافت خواهیم کرد.
اگر یک فایل خالی یا 404 پیدا کردیم، باید آن را برطرف کنیم.
اگر فایل معتبری را پیدا کردیم، احتمالاً روی تنظیمات پیش فرض تنظیم شده است.
اگر فایل robots.txt را نداریم، باید آن را از ابتدا ایجاد کنیم. برای انجام این کار یک ویرایشگر متن ساده مانند Notepad ( ویندوز )
یا TextEdit ( مک ) باز می کنیم.برای انجام این کار فقط از یک ویرایشگر متن ساده استفاده می کنیم. اگر از برنامه هایی مانند:مایکروسافت
ورد استفاده کنیم، برنامه میتواند کد اضافی را در متن وارد کند.Editpad.org یک گزینه رایگان عالی است و در این مقاله از آن استفاده می کنیم.
اگر فایل robots.txt را داریم، باید آن را در دایرکتوری root سایت خود بیابیم.
اگر به جستجو در کد منبع عادت نداشته باشیم، ممکن است پیدا کردن نسخه قابل ویرایش فایل robots.txt کمی دشوار باشد.
معمولاً می توانیم دایرکتوری root خود را با لاگین در حساب میزبانی و رفتن به بخش مدیریت فایل یا FTP سایت خود پیدا کنیم.
فایل robots.txt خود را پیدا می کنیم و آن را برای ویرایش باز می کنیم. تمام متن را حذف می کنیم، اما فایل را نگه می داریم.
اگر از وردپرس استفاده می کنیم، ممکن است هنگام رفتن به yoursite.com/robots.txt فایل robots.txt را می بینیم اما
نمیتوانیم آن را در فایلهای خود پیدا کنیم.این به این دلیل است که در صورتیکه فایل robots.txt در فهرست اصلی وجود
نداشته باشد، وردپرس یک فایل robots.txt مجازی ایجاد می کند. بنابراین باید یک فایل robots.txt جدید ایجاد کنیم.
ایجاد فایل robots.txt
همانطور که گفتیم می توانیم با استفاده از ویرایشگر متن ساده دلخواه، یک فایل robots.txt جدید ایجاد کنیم.اگر از قبل یک
فایل robots.txt داشته باشیم، باید مطمئن شویم که متن را حذف کرده ایم ( اما نه خود فایل را ).سینتکس Robots.txt را می توان
به عنوان "زبان" فایل های robots.txt در نظر گرفت. پنج اصطلاح رایج وجود دارد که احتمالاً در فایل ربات ها با آنها روبرو
خواهیم شد. این اصطلاحات عبارتند از:
User-agent: خزنده وب خاصی که دستورالعملهای خزیدن را به آن میدهیم (معمولاً یک موتور جستجو).
Disallow: این دستور به یک user-agent میگوید که در URL خاص نخزد. فقط یک " Disallow:" برای هر URL مجاز است.
Allow (فقط برای Googlebot قابل اجراست): دستوری که به Googlebot می گوید که می تواند به یک صفحه یا زیرپوشه
دسترسی داشته باشد حتی اگر صفحه اصلی یا زیرپوشه آن غیرمجاز باشد.
Crawl-Delay: یک خزنده باید چند ثانیه قبل از بارگیری و خزیدن منتظر بماند. توجه داشته باشید که Googlebot این دستور را تأیید نمی کند، اما
نرخ خزیدن را می توان در Google Search Console تنظیم کرد.
نقشه سایت: برای فراخوانی مکان sitemap XML مرتبط با این URL استفاده می شود. توجه داشته باشیم که این دستورفقط توسط Google،
Ask، Bing و Yahoo پشتیبانی می شود.می خواهیم یک فایل robot.txt ساده را تنظیم کنیم و سپس به سفارشی سازی آن برای سئو می پردازیم.
با تنظیم عبارت user-agent شروع می کنیم. ما آن را طوری تنظیم می کنیم که برای همه ربات های وب اعمال شود،این کار را با استفاده از
یک ستاره بعد از عبارت user-agent انجام می دهیم:
User-agent: *
سپس، “Disallow:” را تایپ می کنیم اما بعد از آن چیزی تایپ نمی کنیم.
Disallow:
از آنجایی که پس از disallow چیزی وجود ندارد، ربات های وب می توانند درکل سایت ما بخزند. تا اینجا، فایل robots.txt ما باید به شکل زیر باشد:
User-agent:*
Disallow:
درحالیکه بسیار ساده به نظر می رسد، اما این دو خط کارهای زیادی را انجام می دهند.همچنین می توانیم به نقشه سایت XML خود
پیوند دهیم، البته ضروری نیست، اما اگر بخواهیم این کار را انجام دهیم، میبایست این خط را تایپ کنیم:
Sitemap: https://yoursite.com/sitemap.xml
این فایل کوچک، یک فایل robots.txt ابتدایی است. در مرحله بعد می خواهیم این فایل کوچک را به یک تقویت کننده سئو تبدیل کنیم.
بهینه سازی robots.txt برای سئو
نحوه بهینه سازی robots.txt به محتوایی که در سایت خود داریم بستگی دارد. روش هایی برای استفاده از robots.txt وجود دارد.
در ادامه به بررسی برخی از رایج ترین راه های استفاده از آن می پردازیم.باید به خاطر داشته باشیم که نباید از robots.txt به منظور
مسدود کردن صفحات برای موتورهای جستجو استفاده کنیم. یکی از بهترین کاربردهای فایل robots.txt، به حداکثر رساندن
بودجه خزیدن موتورهای جستجو از طریق مسدود کردن صفحاتی است که برای عموم نمایش داده نمی شوند.
به عنوان مثال صفحه لاگین ( wp-admin ) را غیرمجاز می کنیم.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
از آنجایی که از این صفحه فقط برای ورود به قسمت بک اند سایت استفاده می شود، منطقی نیست که ربات های موتور جستجو وقت خود را برای
خزیدن در آن تلف کنند.اگراز وردپرس استفاده می کنیم، می توانیم از همان خط disallow استفاده نماییم.می توانیم از دستور مشابهی برای
جلوگیری از خزیدن ربات ها در صفحات خاص استفاده کنیم. پس از disallow، بخشی از URL را که بعد از .com می آید، وارد می کنیم
و آن را بین دو اسلش قرار می دهیم.بنابراین اگر می خواهیم به یک ربات بگوییم که در صفحه http://yoursite.com/page/ نخزد
می توانیم خط زیر را تایپ کنیم:
Disallow: /page
ممکن است بپرسیم که از ایندکس شدن چه نوع صفحاتی جلوگیری کنیم. در اینجا چند سناریوی رایج وجود دارد که ممکن است اتفاق بیفتد:
1.محتوای تکراری
در حالی که محتوای تکراری تأثیر منفی در سئو سایت دارد، موارد انگشت شماری وجود دارند که در آنها محتوای تکراری ضروری و قابل قبول است.
به عنوان مثال، اگر نسخه چاپگر یک صفحه را داریم، از نظر فنی محتوای تکراری داریم. در این مورد، می توانیم به رباتها بگوییم که در یکی
از آن نسخه ها ( معمولاً نسخه مناسب چاپگر ) نخزند.
2.صفحات تشکر
یکی از صفحات مورد علاقه بازاریابان، صفحات تشکر است. زیرا به معنای یک سرنخ جدید است.همانطور که مشخص است، برخی از
صفحات تشکر از طریق گوگل قابل دسترسی هستند. این بدان معناست که افراد می توانند بدون گذراندن فرآیند جذب سرنخ به این صفحات
دسترسی داشته باشند و این اصلاً خوب نیست.با مسدود کردن صفحات تشکر، مطمئن می شویم که فقط سرنخ های واجد شرایط آنها را می بینند.
فرض می کنیم صفحه تشکر ما در https://yoursite.com/thank-you/ پیدا شده است. در فایل robots.txt، مسدود کردن
این صفحه به شکل زیر است:
ـــ Disallow: /thank-you
ـــ دو دستورالعمل دیگر وجود دارد که باید بدانیم: noindex و nofollow.
ـــ دستورالعمل disallow در واقع از ایندکس شدن صفحه جلوگیری نمی کند.
بنابراین از نظر تئوری، ما می توانیم یک صفحه را disallow کنیم، اما همچنان ایندکس شود. قطعاً ما چنین چیزی را نمی خواهیم. به همین دلیل است که
به دستورالعمل noindex نیاز داریم. این دستورالعمل با دستورالعمل Disallow کار می کند تا مطمئن شود ربات ها صفحات خاصی را ایندکس نمی کنند.
اگر صفحاتی داریم که نمیخواهیم ایندکس شوند ( مانند صفحات تشکر )، می توانیم از دستورالعملهای Disallow و Noindex استفاده کنیم:
Disallow: /thank-you
Noindex: /thank-you
اکنون، صفحه مورد نظر در SERP ها نشان داده نمی شود.
دستورالعمل nofollow در واقع همان لینک nofollow است. این دستورالعمل، به رباتهای وب می گوید که در پیوندهای یک صفحه نخزند.
البته پیاده سازی دستور nofollow کمی متفاوت است، زیرا در واقع بخشی از فایل robots.txt نیست.
ابتدا باید کد صفحه ای را که می خواهیم تغییر دهیم، پیدا کنیم. در بین تگ های کد زیر را قرار می دهیم.
اگر بخواهیم هر دو دستورالعمل noindex و nofollow را اضافه کنیم، از کد زیر استفاده می نماییم:

تست نهایی
در پایان، میبایست فایل robots.txt خود را آزمایش کنیم تا مطمئن شویم که همه چیز معتبر است و به درستی کار می کند.
Google یک آزمایش کننده robots.txt رایگان را به عنوان بخشی از ابزارهای Webmaster ارائه می کند.
ابتدا با کلیک بر روی "Sign In" در گوشه سمت راست بالا وارد حساب کاربری سرچ کنسول و یا صفحه تست robots.txt می شویم.
سپس Property خود را (به عنوان مثال، website.com) انتخاب می کنیم و روی "test" در سمت راست پایین صفحه کلیک می کنیم.
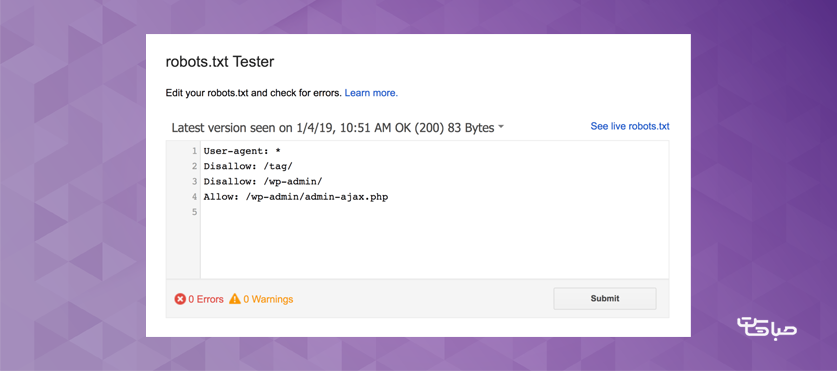
اگر متن “Test” به “Allowed” تغییر کرد، به این معنی است که robots.txt ما معتبر است.
در پایان، robots.txt خود را در دایرکتوری root آپلود می کنیم.
راهکار صباهاست
انتخاب هاست مناسب می تواند تأثیر مثبت بر سئوی سایت داشته باشد. یکی فاکتورهای تأثیرگذار در سئوی سایت، سرعت است.
هاست وردپرس صباهاست با بهره گیری از منابع سخت افزاری قدرتمند همچون هاردهای فوق پرسرعت NVMe سرعت وب سایت
وردپرسی ما را تا 5 برابر افزایش می دهد.
آپ تایم بالا و نزدیک به 100% از دیگر عوامل تأثیرگذار در سئو سایت است. آپ تایم بالا یکی دیگر از ویژگی های قابل توجه
هاست وردپرس صباهاست است. همچنین هاست وردپرس صباهاست با داشتن ویژگی هایی همچون فایروال اختصاصی برای جلوگیری از حملات DDoS و
پیاده سازی Waf اختصاصی و بک آپ گیری خودکار و منظم امنیت وب سایت وردپرسی را تأمین می نماید.
جمع بندی
یکی از روش های بهبود سئو سایت، ایجاد فایل robots.txt است. استفاده از فایل robots.txt می تواند تأثیر چشمگیری در سئو سایت ما داشته باشد.
در این مقاله در مورد فایل robots.txt، علت اهمیت و نحوه ایجاد و روش های استفاده از آن توضیحات کاملی عنوان شد.
در پایان نحوه تست فایل robots.txt شرح داده شد.
امیدواریم این مقاله برایتان مفید واقع شده باشد. اگر سوالی دارید که در این مقاله پاسخش را پیدا نکردید، در قسمت کامنت ها سوال
خود را مطرح کنید، کارشناسان ما در کمتر از چند دقیقه به سوالات پاسخ خواهند داد.
این مقاله را با دوستان خود به اشتراک بگذارید.
موفق باشید.


.png)